MySQL 面试题
1. MySQL是怎么执行一条SQL语句
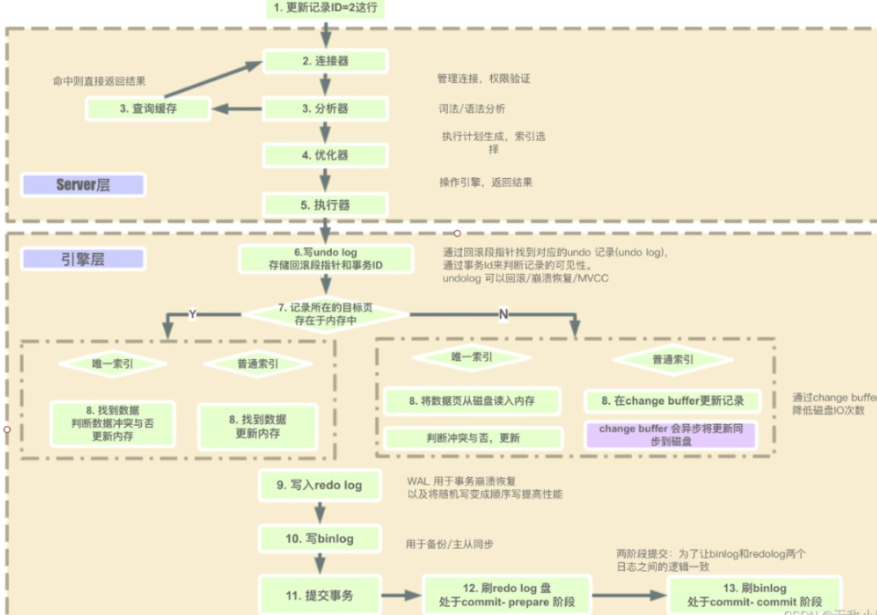
连接管理与权限验证
- 客户端与 MySQL 服务器建立连接,服务器会验证客户端的身份和权限,只有通过验证的用户才能执行后续操作。
解析
- 词法分析:MySQL 将输入的 SQL 语句按照词法规则进行拆分,识别出关键字、标识符、常量等。例如,对于语句
SELECT * FROM users WHERE age > 18;,会将其拆分为SELECT(关键字)、*(通配符)、FROM(关键字)、users(表名,标识符)等。 - 语法分析:根据 MySQL 的语法规则,对词法分析后的结果进行语法检查和结构分析,构建出对应的解析树。如果 SQL 语句语法错误,在此阶段就会被发现并返回错误信息。
- 词法分析:MySQL 将输入的 SQL 语句按照词法规则进行拆分,识别出关键字、标识符、常量等。例如,对于语句
查询优化
- 逻辑优化:对解析树进行优化,例如简化查询条件、消除冗余的子查询或视图等。如查询
SELECT * FROM (SELECT * FROM users) AS t;,会被优化为SELECT * FROM users;。 - 物理优化:根据表的索引、数据分布等信息,选择最优的查询执行计划,包括决定使用何种索引、连接方式以及表的扫描顺序等。例如,若users表的age字段上有索引,对于
SELECT * FROM users WHERE age > 18;语句,优化器可能会选择使用该索引来快速定位满足条件的记录。
- 逻辑优化:对解析树进行优化,例如简化查询条件、消除冗余的子查询或视图等。如查询
查询执行
- 按照优化后的执行计划,调用存储引擎的接口来获取数据。如果需要进行表连接、排序、分组等操作,在这个阶段会按照相应的算法进行处理。例如,使用嵌套循环连接算法来连接多个表,使用快速排序算法对结果集进行排序等。
结果集返回
- 将查询结果返回给客户端。如果查询语句是INSERT、UPDATE、DELETE等修改数据的操作,则返回受影响的行数等信息。
- undo log, mvcc
- redolog,wal
- binlog,备份,主从
2. redo log
redo log 是 MySQL 用于保证数据持久性的一种机制。在 MySQL 中,每当有一条记录被更新,MySQL 都会先写入 redo log,然后再更新内存,以此来确保数据持久性。当事务提交时,redo log 被写入磁盘,并清空,以保证数据完整性。
- 事务持久性
- 数据一致性,完整性
- 崩溃恢复, 恢复数据库最后一次正常运行的状态,通过执行redo log记录的操作. 重播机制.
- 性能优化, redo log 减少随机写,改成顺序写,提高性能,减少磁盘 IO。异步刷新redo buffer.
innodb_flush_log_at_trx_commit=1,表示每次事务提交时,都将 redo log 写入磁盘。innodb_flush_log_at_trx_commit=0,表示系统崩溃时,只有 redo log 未写入磁盘,数据可能丢失。
innodb 内存 -> redo log -> 磁盘
3. 为什么不能使用自增ID或者UUID做MySQL的主键,雪花算法生成的主键存在哪些问题
- 在MySQL的分布式架构中,为什么不能使用自增主键
- UUID可以用来做主键吗? 存在哪些问题?
- 雪花算法生成的主键存在哪些问题?snowFlake 算法的原理,介绍一下它有哪些优势和不足?
case1: 自增ID
create table if not exists t1 (
id int auto_increment primary key,
name varchar(20)
) engine=innodb default charset=utf8mb4;
3.1 UUID可以用来做主键吗? 存在哪些问题?
UUID 是随机生成的,每次当插入记录时,需要查找定位位置,会导致数据写入效率低下,并且可能伴随着数据的移动. 不同于自增的数据的批量插入,直接定位数据,顺序插入,比UUID插入的效率高。
UUID 是由 32个十六进制数字和4个连字符组成的,不好阅读.
3.2 雪花算法原理?
分布式 ID 生成算法
工作原理:
- 当前时间戳
- 机器标识
- 序列号
当需要生成一个 ID 时,算法首先获取当前的时间戳,然后根据工作机器 ID 和序列号生成一个唯一的 ID。如果在同一毫秒内有多个 ID 需要生成,序列号会自动递增,以确保每个 ID 都是唯一的。如果序列号达到了最大值,算法会等待下一个毫秒的到来,然后重新从 0 开始计数。
缺点:
- 依赖时钟,如果时钟回拨,会存在id重复的情况。
- 存储的时间最长 69年,存在用尽的可能。