写给数据产品经理新人的工作笔记
链接: https://zhuanlan.zhihu.com/p/415748027
作者
陈文思,数据圈非著名“大表姐”,应用统计学及应用心理学双向专业背景。
以网站分析师入行,从业十年间从数据采集到指标体系,从数据集市到数据分析、数据运营等方向均有涉及。曾就职于凡客诚品、汽车之家、理想汽车、美团点评。
第1章 成为数据产品经理:角色创建和角色转变
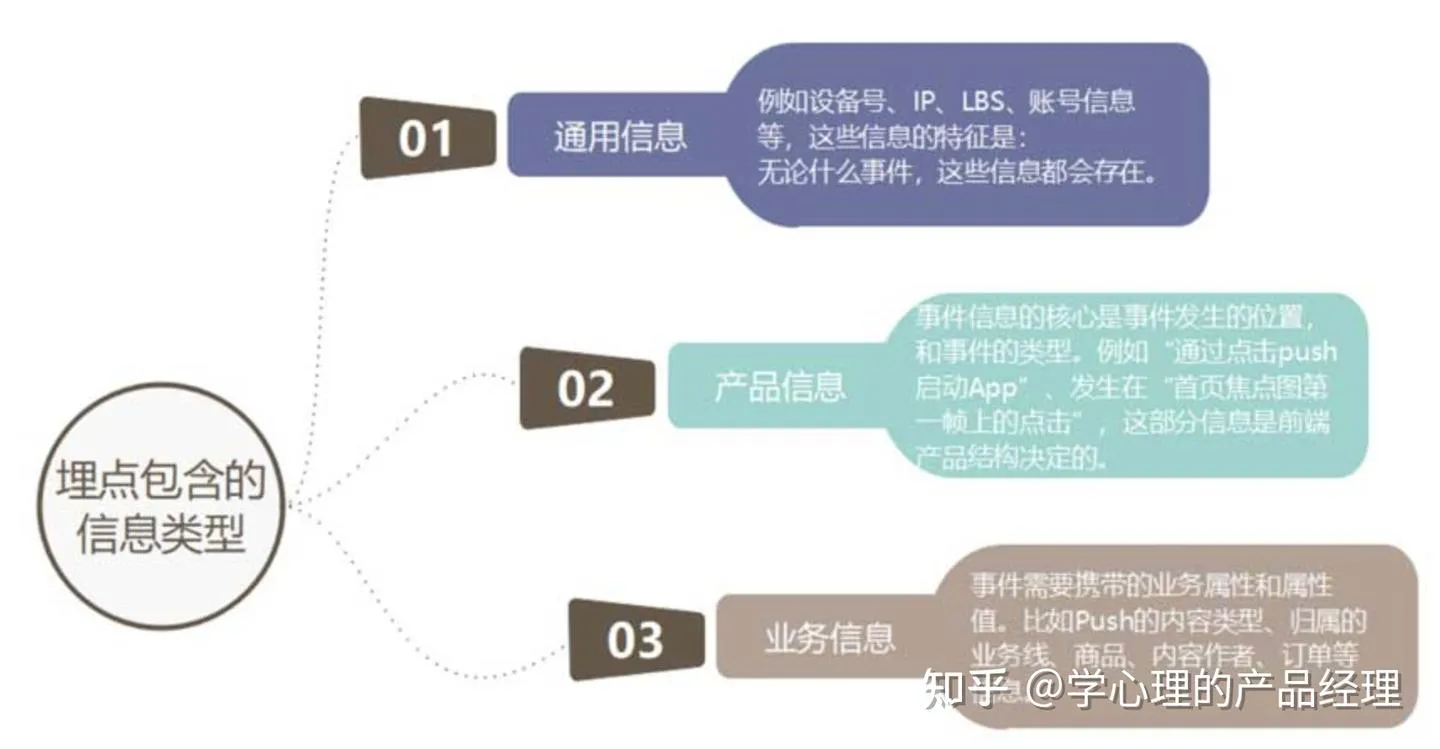
数据产品按照功能可以分为:
● 数据管理工具(元数据、埋点管理、SLA等);
● 基础工具(查询、报表、数据订阅);
● 可视化工具(多数人对数据产品的概念仅限于此);
● 策略应用工具(多版本测试等)。
按照开发者分:
● 原生型数据产品经理, 从入行就是
● 分析型数据产品经理,从数据分析师转型做数据产品经理 ● 技术型数据产品经理,从平台数据技术转型 ● 产品型数据产品经理,从其他类型的产品经理转型 数据产品经理的技能
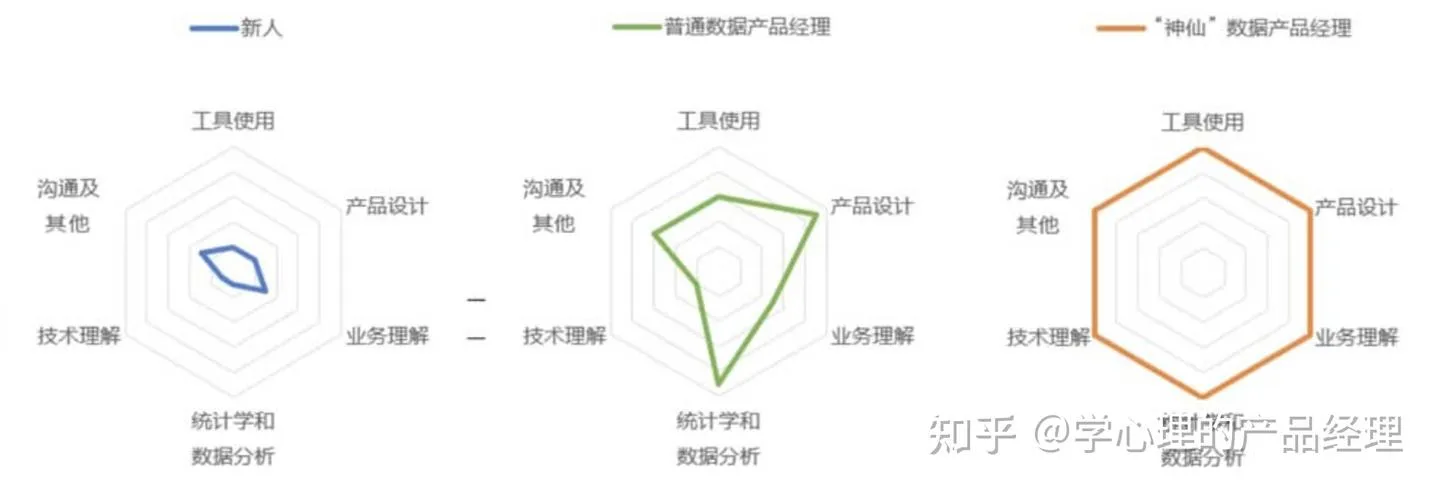
数据产品经理的技能雷达图 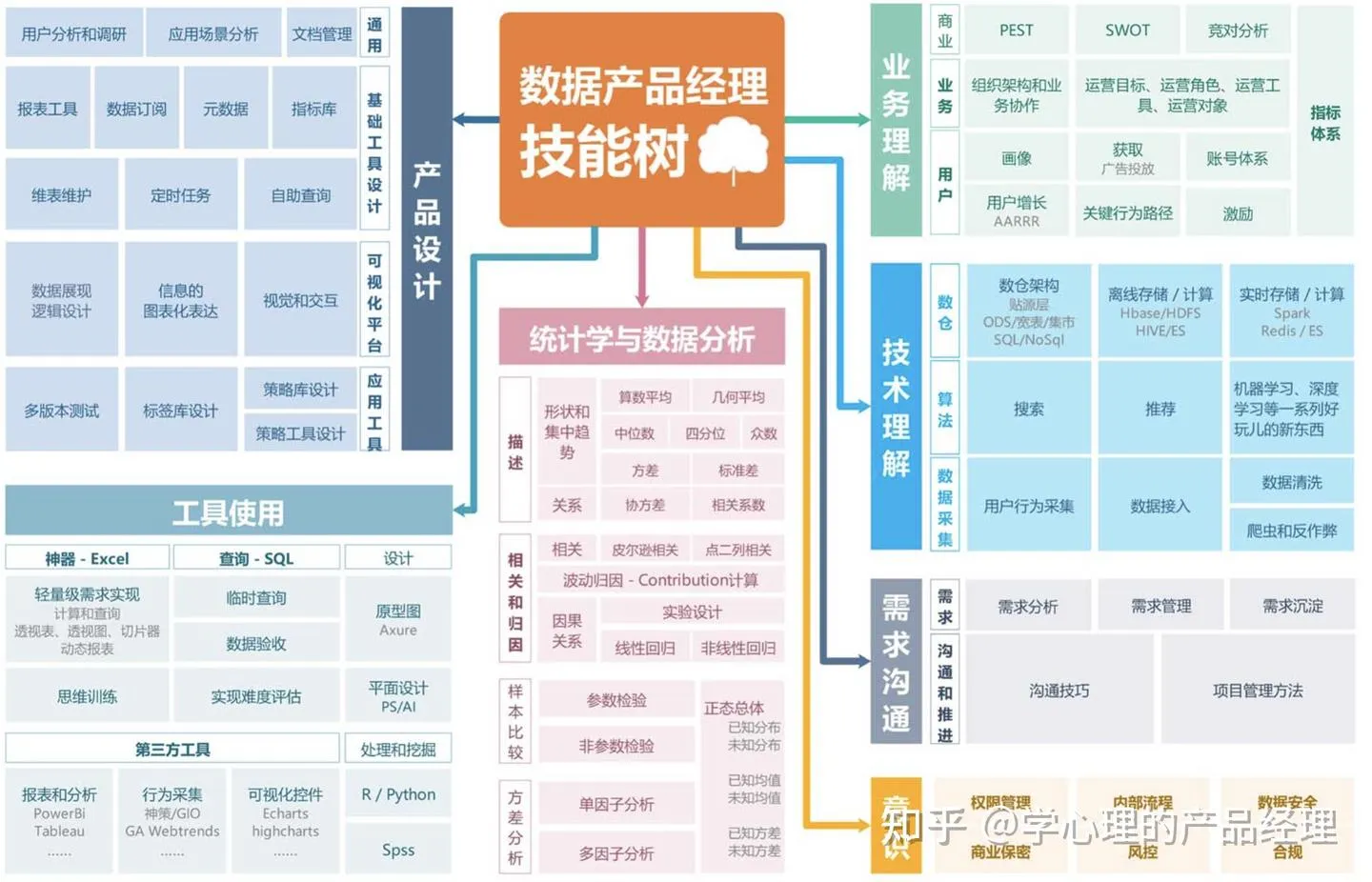 数据产品经理技能树
数据产品经理技能树
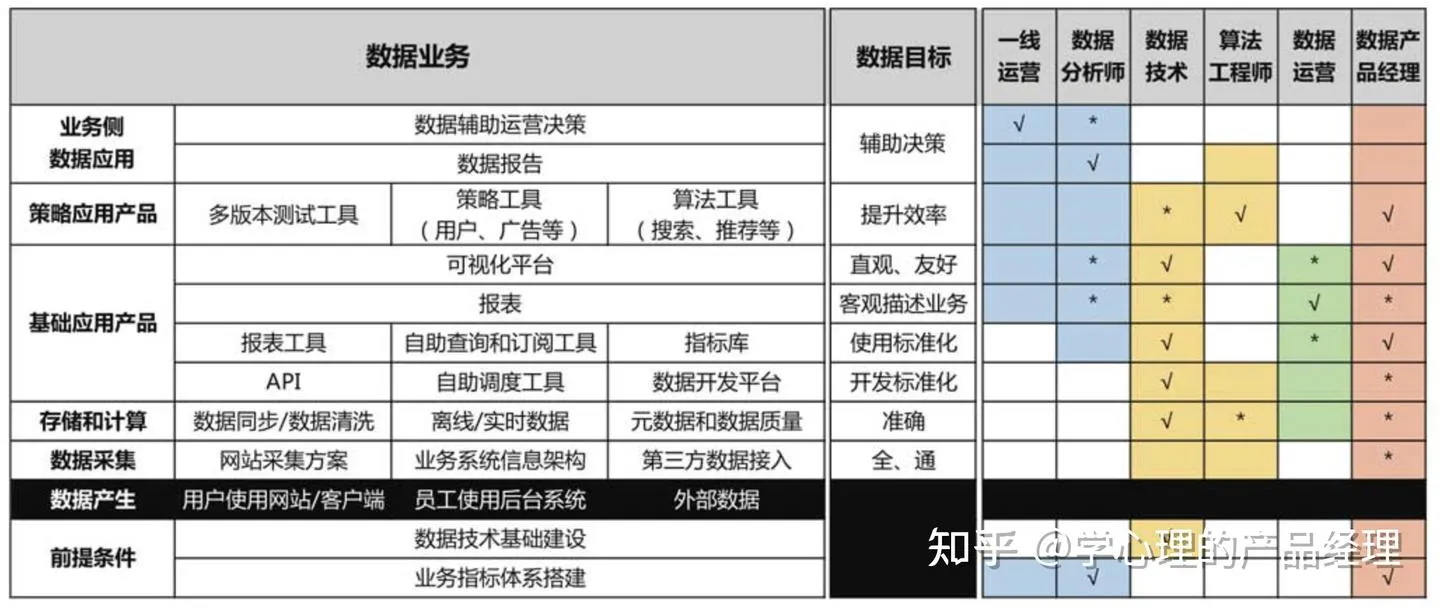
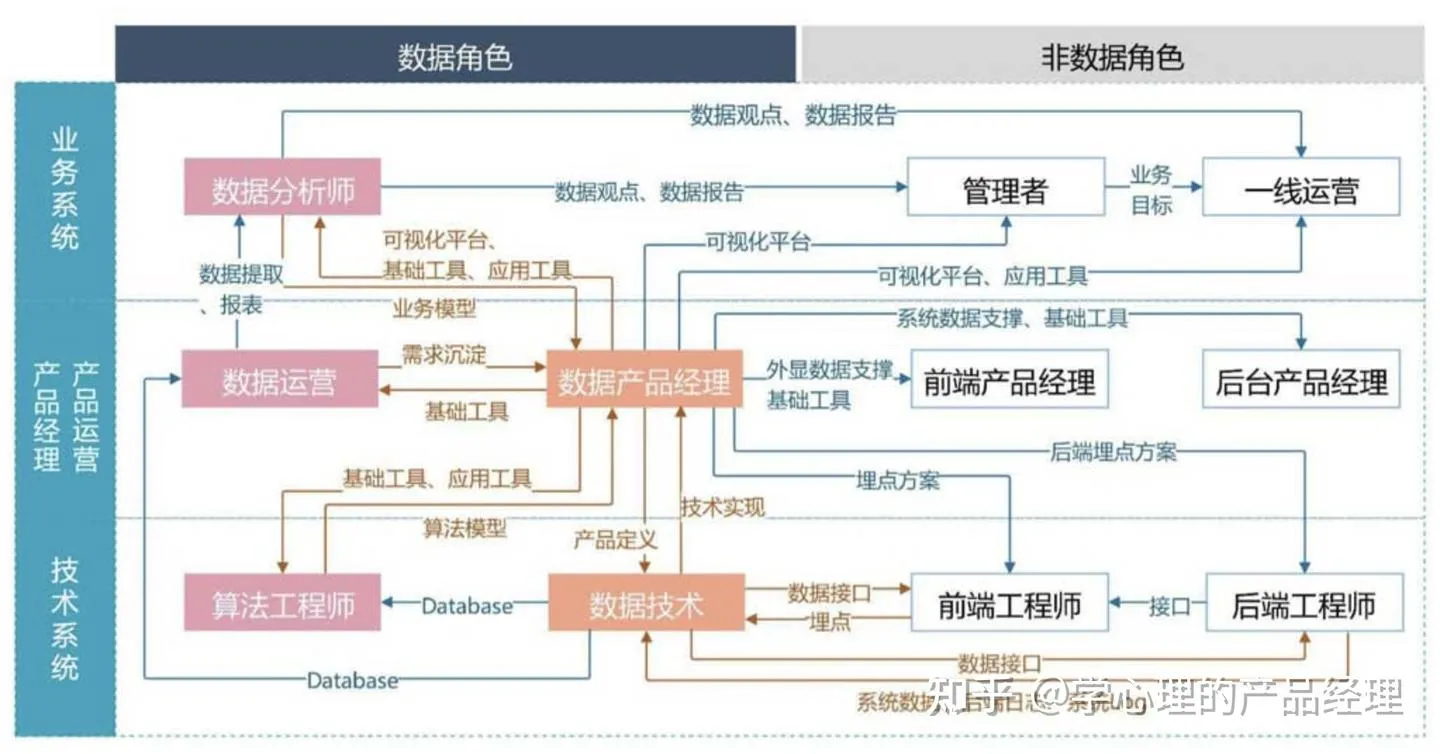
第2章 数据产品经理和其他角色的关系
第3章 需求沟通过程
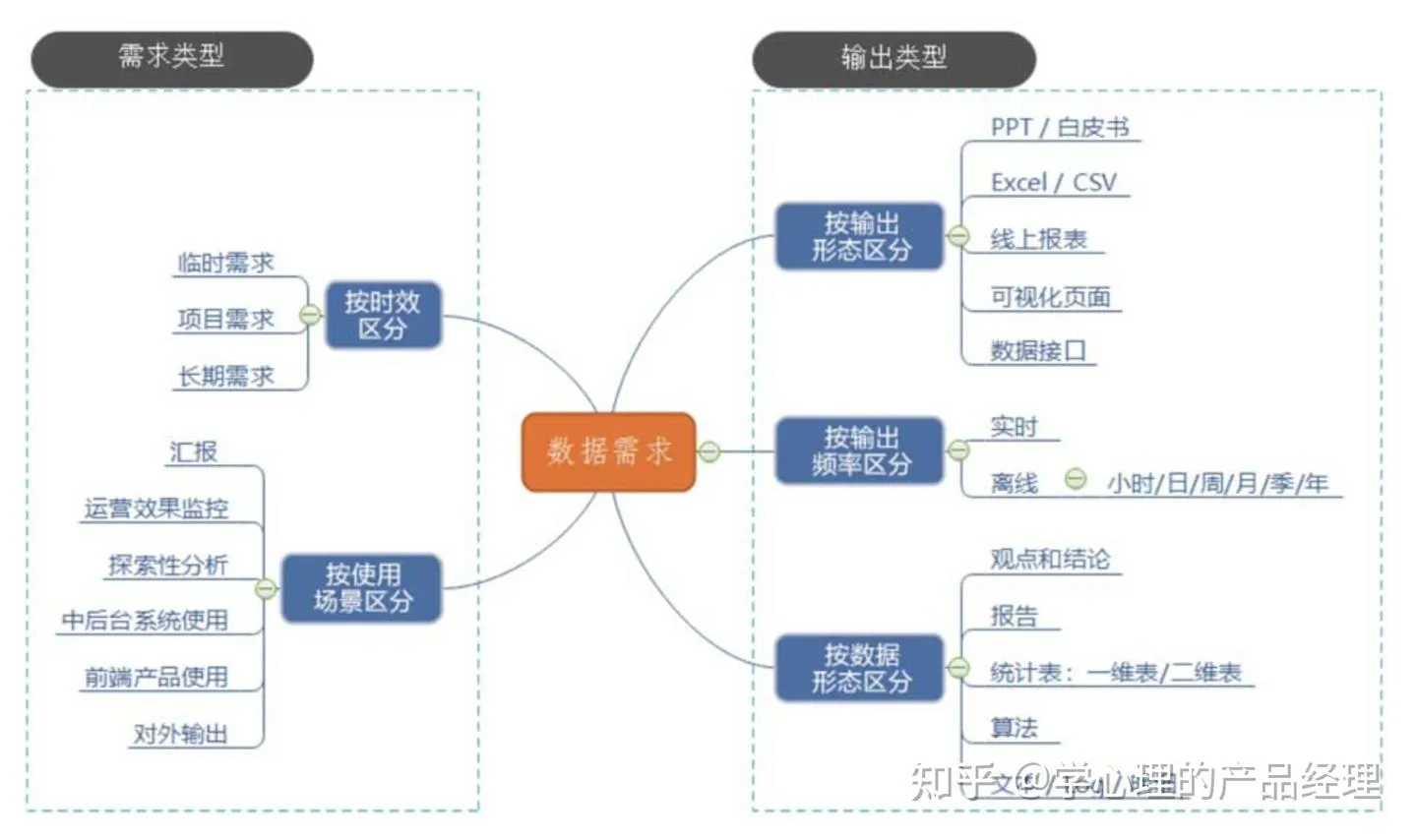 数据需求
数据需求
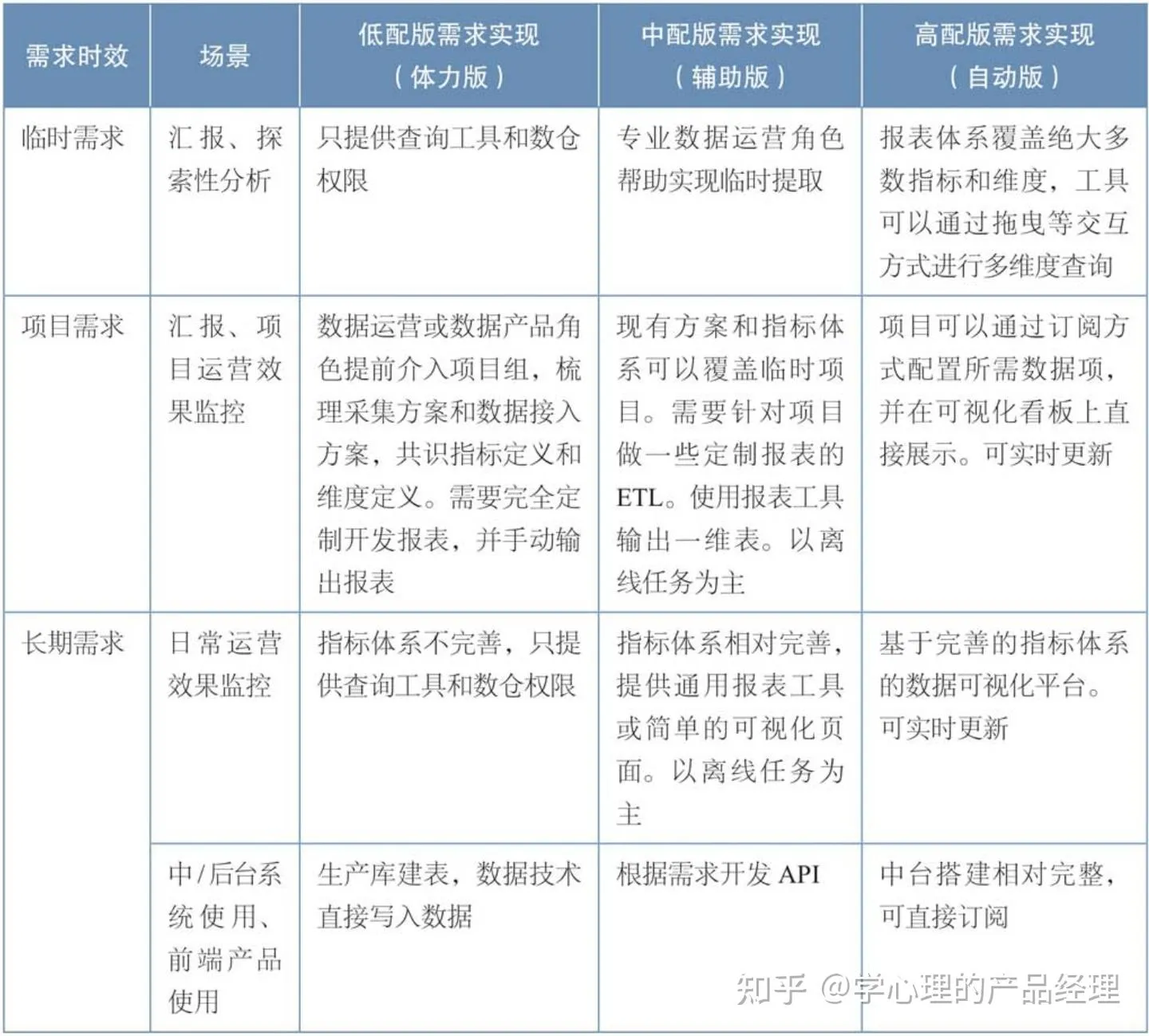 不同需求类型对应的实现方式
不同需求类型对应的实现方式 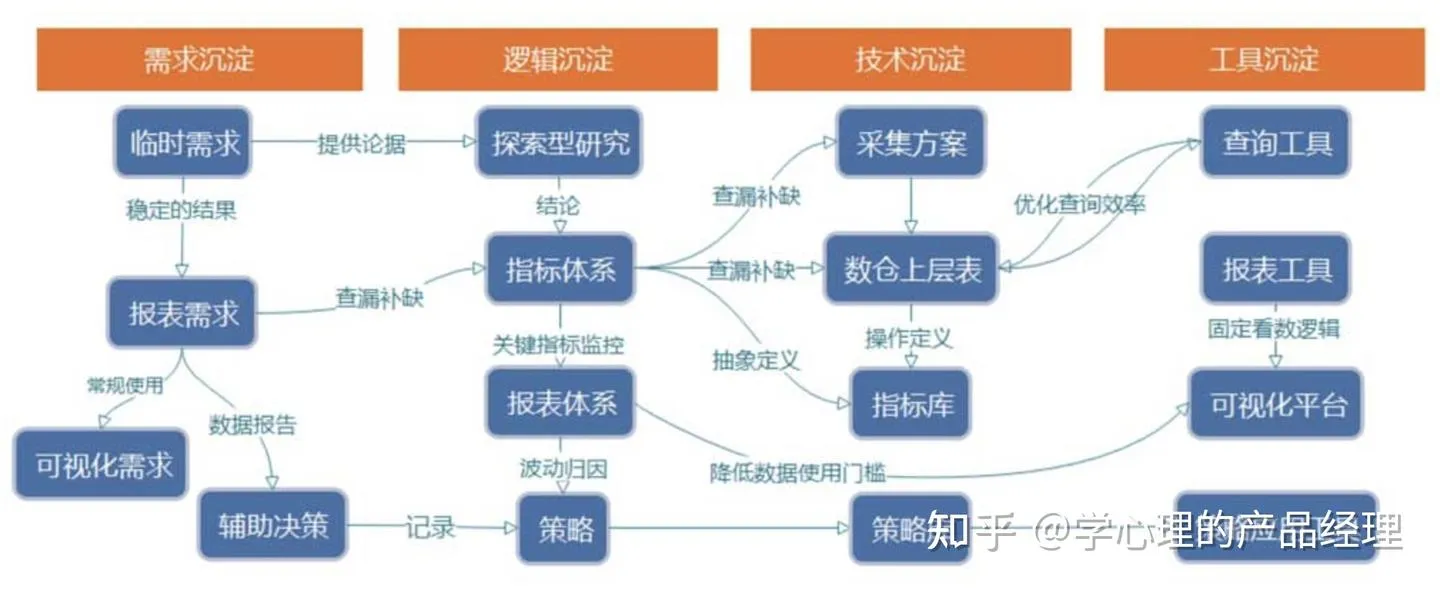
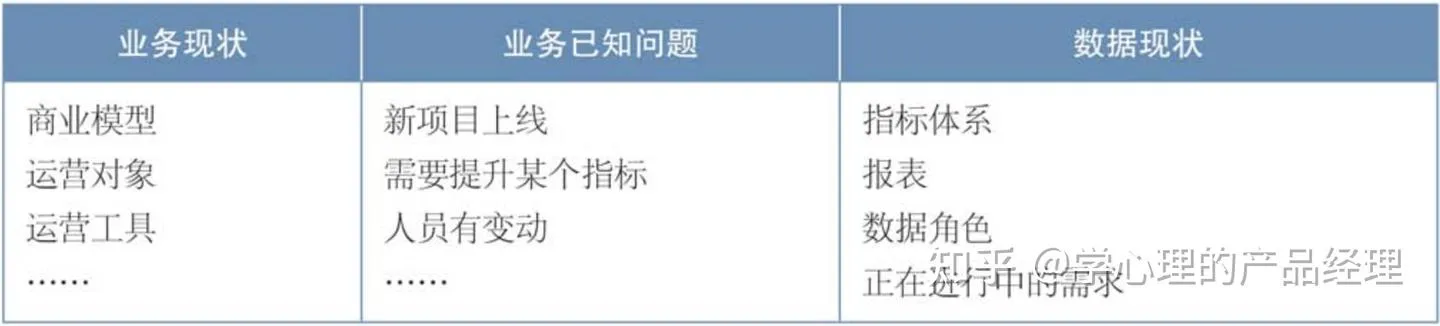
需求沟通前的准备 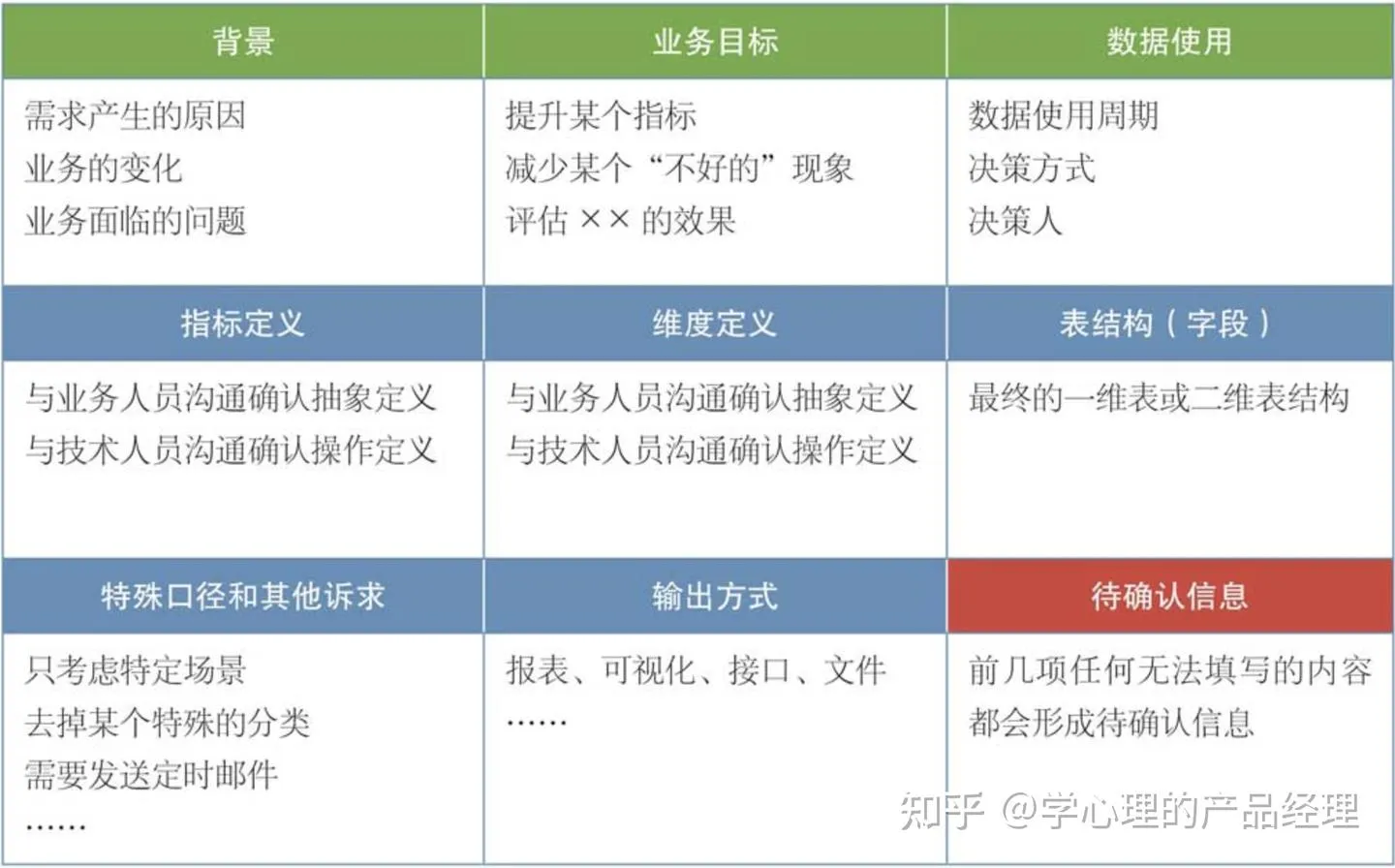
需求沟通记录
第4章 指标体系搭建
从作用上讲,指标体系为公司战略和业务运营提供的是一种【方向感】:有指向、有诊断。 总结出指标体系制定的基本方法:
- 确立描述的目标。
- 选择描述这个目标的核心指标。
- 除了描述“量”的指标,还要选择至少一个描述“质量”的指标。
- 确保选择的指标具有可执行性:可追踪、可比较。
- 指标之间具有一定的独立性:具有高相关性的指标,只选择一个即可。
案例:某媒体网站的指标体系搭建
首先,确立描述的目标:①用户规模;②内容质量;③广告效果。
然后,为每个目标选取核心指标。以用户规模为例,可以使用独立访客量(UV)。但是由于业务处于上升期,目标是“扩大用户规模”,新增访客量也是核心指标。描述访客的“质量”可以使用访问深度指标来描述,比如人均播放量、人均阅读量、人均互动量、平均访问时长等。描述新增访客的质量,除了访问深度,还要有“留存率”指标。新增访客量×留存率,才是比较真实的规模增长。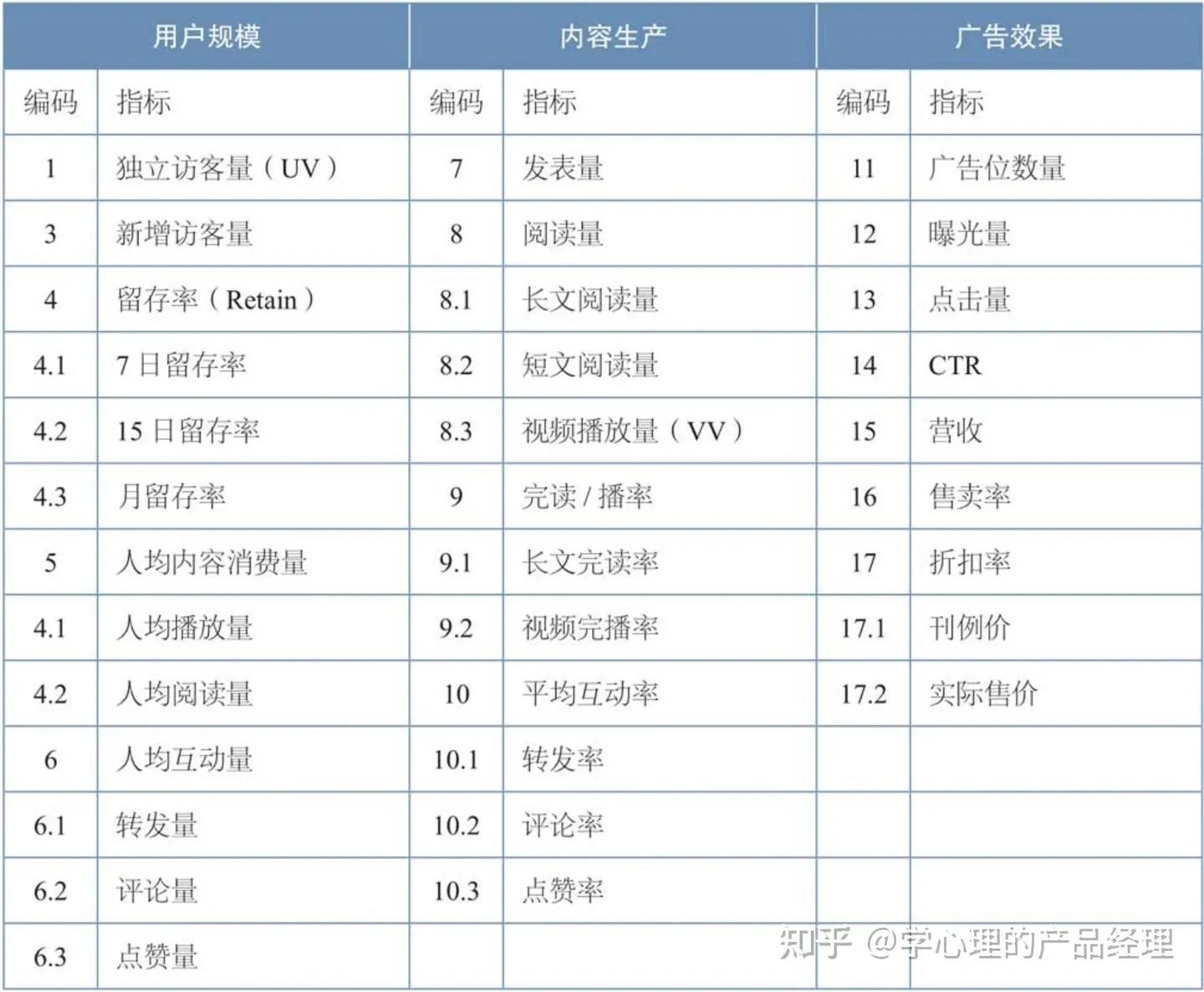
选好了指标,这些指标需要选取哪些维度来建立监控,是由业务模型中的【关键要素】决定的。例如,某家网站是分城市运营的,那么城市就一定是一个关键维度;站外流量的引流,是根据不同渠道引入的,那么流量来源站就是独立访客量和新增访客量的关键维度;如果我们投放了SEM,那么搜索关键字也是一个关键维度。在内容生产上,如果是按照内容类型运营的,那么内容的分类就是一个关键维度;如果我们要运营PGC的内容作者,那么内容生产相关的指标就要拆分到作者维度。 指标体系存在4个阶段。
- 客观描述:客观描述业务。
- 发现问题:建立监控并从中发现问题,辅助运营。
- 策略沉淀:记录指标变化和业务决策之间的关系。
- 数据驱动:发现业务决策的规律,并实现一定程度的系统化和自动化决策。
从第1阶段到第2阶段,要不停细化指标体系,并建立相应的监控。
从第2阶段到第3阶段,要在做波动归因的同时,详细记录每一个波动是什么因素带来的,每一个业务动作是基于什么样的数据表现。
从第3阶段到第4阶段,重点是发现业务决策的内在规律。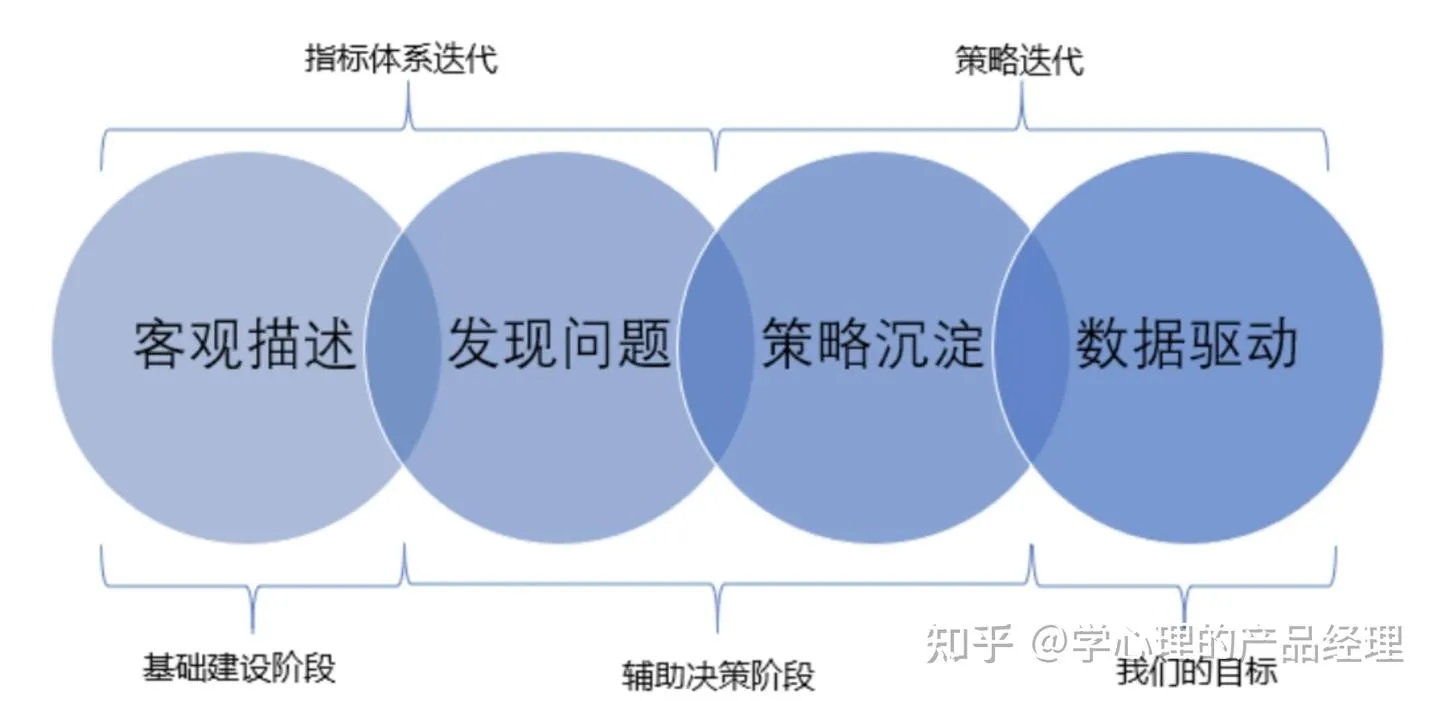
前两个阶段服务的是指标体系本身的迭代,后两个阶段服务的是策略迭代。通过对指标的监控和策略的沉淀辅助运营,是数据的辅助决策阶段。最终可以把决策过程系统化、自动化,是数据体系的一个目标。
第5章 Excel是最完美的数据产品
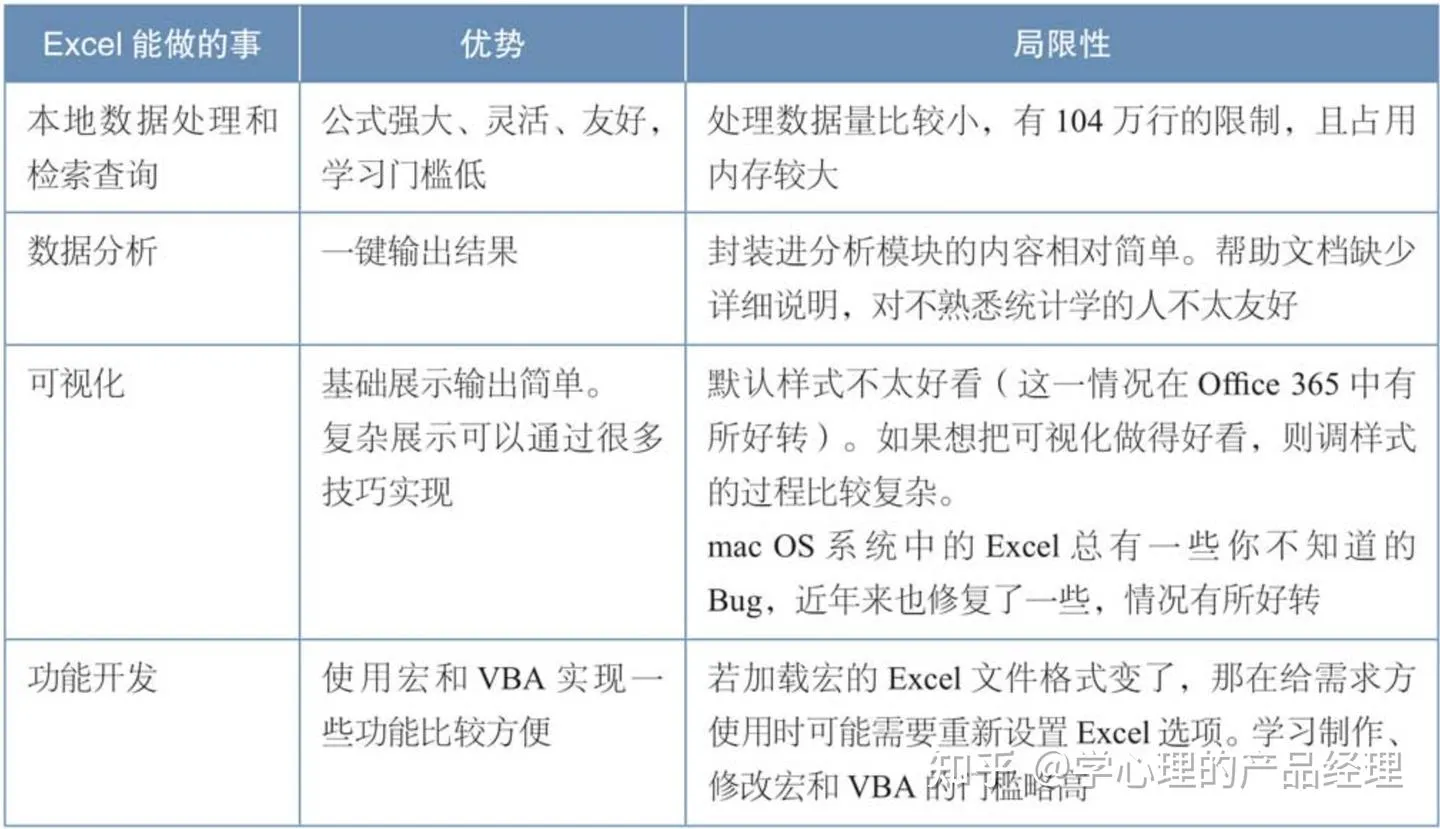

如果你需要对海量数据进行查询、计算、预处理,就用Hive;如果你要在本地处理较大量数据,就用SPSS或者R;如果你需要建立复杂的模型,就用SAS、R、Python、MATLAB等;如果你要处理大量文本,就用Python和PHP;但是,如果你需要一个完整的、本地的微型“数据产品”,Excel再完美不过,这是其他任何一个产品都做不到的,至少做不到这么好。
可以从以下两个方面总结出Excel最适合做什么。
(1)从需求实现的角度:Excel适合实现数据量较小的报表、数据分析、可视化需求。其中,“数据量较小”可以粗略地定义为,完整制作后的文件大小在2MB以下,1MB左右最好,目的是便于发送邮件。另外,在技术资源紧张,提供给需求方的通用工具准备不足时,或者在需求频繁调整的阶段,Excel可以作为一种相对简单的临时实现方法出现来“填缝”,可以在一定程度上减少占用大量开发资源实现临时数据需求的尴尬情况发生。
(2)从产品思维的角度:Excel可以在本地模拟出从数据采集到数据仓库报表,再到数据可视化的全过程。
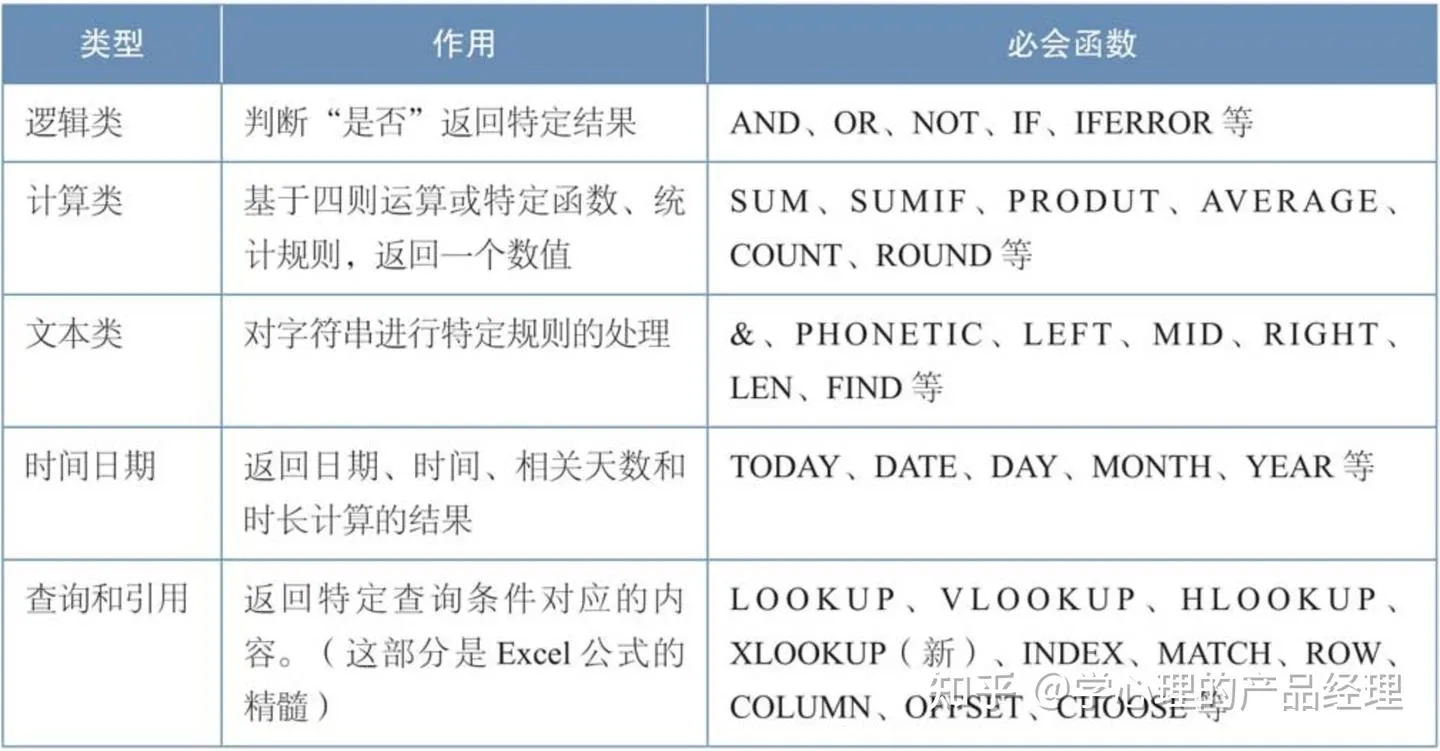
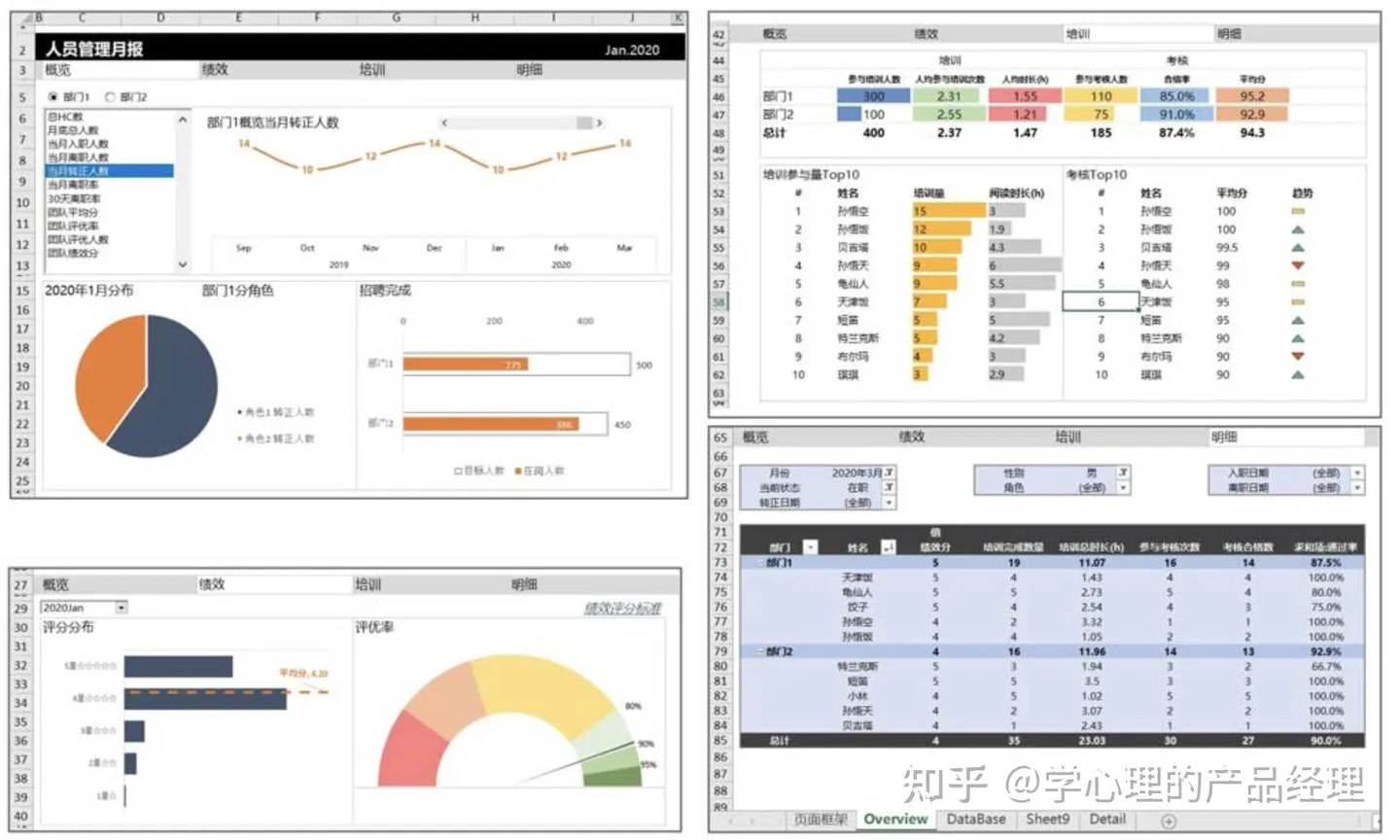
用Excel实现一个迷你可视化产品的过程,对于刚刚上手的新人来说,是非常好的训练工具。在一些特殊场景下(如数据量不大、业务模型不稳定、开发资源紧缺等),这个方法也可以作为一个省钱、省资源的“草根版”的可视化产品方案。
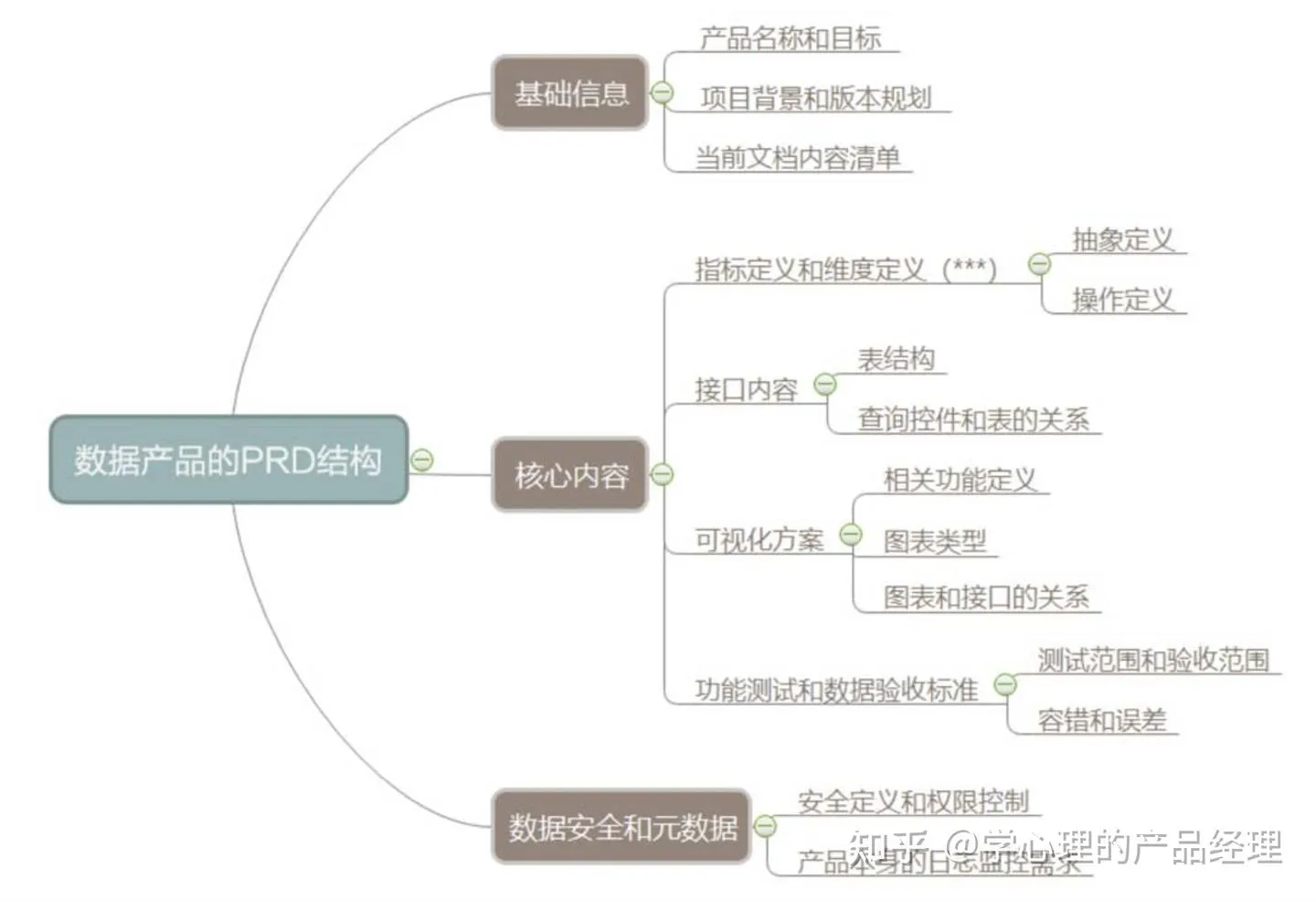
第6章 不同的工具解决不同的问题
第7章 数据应用和第三方平台
DMP的全称是Data Management Platform(数据管理平台)。 
第8章 必须理解的统计学知识
贝叶斯法则:它描述的是“事件A以事件B为条件发生的概率”和“事件B以事件A为条件发生的概率”之间的关系。
贝叶斯法则还可以表述为:后验概率=标准相似度×先验概率。
其中,“先验概率”是指根据以往经验得到的概率。
经验除了历史数据,还有一部分是“主观的知识体系”决定的。也就是说,贝叶斯把主观意愿引入了统计学模型,让认知水平参与了统计学计算,并使结果受其约束。
“主观意愿”的出现,好像使数学的严谨性受到了挑战。
第9章 必须了解的数据技术基础知识
数据平台存在的形态:数据平台基础架构
数据平台需要解决的问题都是一致的。
● 数据采集:日志采集和 数据同步;
● 数据清洗和预处理:涉及一系列的规则,本质也是ETL过程; ● 数据的存储:海量的、稳定的存储;
● 数据的离线计算和实时计算;
● 输出方式:接口和自助查询;
● 系统具备相对高的性能和稳定性;
● 数据安全和权限管理。
技术选型
Hadoop仍然是我们最常见的开源分布式架构。
Hadoop设计的核心有两个:HDFS和MapReduce。
通常需要搭配采集框架(例如比较流行的Kafka+Flume)、Hbase数据库、部署配置工具(Ambari)等一系列组件形成一个完整的架构。
HDFS(Hadoop Distributed File System,分布式文件系统)既然是一个“系统”,就会包含一系列的功能和流程。主要由主服务器(NameNode)和负责存储数据的DataNode组成,NameNode负责管理文件系统的命名空间和客户端对文件的访问操作。
MapReduce的本质是一种编程模型,或者说是一种计算方法。作为一个平台组件,它是用并行的方式处理大规模的计算。Flume像个情报员,负责把情报(日志)拿到手交给负责接头的信息员Kafka运送回来,处长HDFS负责接收这些数据,指挥NameNode给它们起好名字并贴上标签,交给档案馆Hbase存起来;
这些数据还可以通过情报分析站MapReduce去做复杂的深度加工,加工好的结论也可以交给Hbase存起来。
而想要使用MapReduce需要通过工具Hive去实现。虽然Hbase是个超大的档案馆,MapReduce也能为这个超大的档案馆提供更多结果,但若是急需这些情报采取行动(需要实时输出这些数据),它们的效率就显得有点慢。
这时Kafka可以使用应急流程,把数据直接交给独立调查员Storm做实时分析,分析好了交给临时档案馆Redis存起来,领导(前端页面)可以去找Redis查阅结果。
可惜的是,Storm和Redis虽然效率很高,却没有Hbase这个档案馆那么庞大和稳定,工资(成本)又太高,至今只能打一打下手,做一些补充工作。
数据源:数据采集和数据同步
- 从结构上说,数据源大概分为两大类,一种是非结构化数据,一种是结构化数据。
- 结构化数据,通俗地说是这些数据已经是表格了;非结构化数据是指我们可以收集到的一切散碎的信息——例如图片、音频、文本,等等。
- 非结构化数据如果想要用于分析,则需要进行结构化。
数据建模:核心思想是“分类”
- 分类逻辑可以分为横向和纵向两种类型。
- 横向分的是层次,纵向分的是主题(或者主体)。
- 这两个方向的分类构成了当前市场上数据仓库的主流分类逻辑。
- 按照数据加工的深度区分“层次”,基于的是相对通用的数据加工步骤。
- 纵向区分“主题”,是基于关键索引和指标体系的。
- 例如用户,会对应一个用户ID,一系列针对用户的宽表和描述用户的指标计算,这些内容放在一起就会形成一个“用户主题”。
- 电商网站会有“订单”主题,资讯类网站会有“内容”主题,平台会有“商家”主题,等等。
第10章 不得不说的“坑”和红线